

概要
- 表形式データに対して、XGBoostなどの決定木のアンサンブルの使用が推奨されています。
- 近年、深層学習を用いたモデルがいくつか提案されており、XGBoostを上回ると主張しています
- 本論文では、様々なデータセットを用いて、新しい深層学習モデルとXGBoostを厳密に比較することで、これらの深層学習モデルが表形式データの推奨オプションとなるべきかどうかを探ります
- 結果的に、深層学習モデルは原論文のデータセットに対する精度は良いが、未知のデータセットに対しての精度は悪かったです。むしろ、XGBoostのほうが、どのデータセットに対しても精度が良く、深層学習モデルを上回りました。
- 一番良いのは、XGBoostと深層学習モデルとのアンサンブルでした。
イントロダクション
深層ニューラルネットワークは、画像、音声、テキストなど、さまざまなドメインで大きな成功を収めています(Devlin:2018年(BERT)、He:2016年(ResNet)、Oord:2016年(Wavenet)) 。行と列から形成される、表形式(tabular)のデータは、実世界のアプリケーションで最も一般的なデータタイプです 。表形式データにディープニューラルネットワークを適用する際には、局所性の欠如(汎化性能の確保)、欠損値の埋め方、特徴の種類の混在(数値、順序、カテゴリ)、データセット構造の事前知識(ドメイン知識)の欠如(テキストや画像の場合とは異なる)など、多くの課題が生じます。
現在、XGBoostなどのツリー・アンサンブル・アルゴリズムは表形式データの問題に対して、一番推奨される選択肢です。しかし、近年では深層学習を表形式データに適用する例が増えており、そのうちのいくつかはXGBoostを上回ると主張されています。この分野の論文では、標準的なベンチマークが存在しないため、通常、異なるデータセットを使用しています。特に、オープンソースの実装がないモデルもあるため、モデルの比較は困難です。
この研究の主な目的は、提案されている深層モデルのうち、どれかが本当に表形式データセットの問題に推奨される選択肢となるべきかどうかを探ることです。この質問には2つの部分があります
(1) 特に、モデルを提案した論文に登場していないデータセットに対して、モデルはより正確なのか?
(2) 他のモデルと比較して、学習やハイパーパラメータ探索にどのくらいの時間がかかるのか?
これらの疑問に答えるためにを最近の4つの論文で提案されたディープモデルをこれらの論文で使われた9つのデータセットを含む11のデータセットで分析しました。
その結果、ほとんどの場合、各モデルはそれぞれの論文で使用されたデータセットでは最高の性能を発揮しますが、他のデータセットでは著しく劣ることがわかりました。また、我々の研究では、XGBoostは通常、これらのデータセットで深層学習モデルを上回ることを示している。さらに、XGBoostではハイパーパラメータの探索プロセスがはるかに短いことを実証しています。一方、深層モデルとXGBoostを組み合わせたアンサンブルの性能を調べ、このアンサンブルが最良の結果を達成することを示しています。最近の顕著な進歩にもかかわらず、表形式のデータに必要なのは深層学習だけではないことを示しています
今回使用する深層学習モデル
- TabNet
- Neural Oblivious Decision Ensembles (NODE) NODEネットワーク
- DNF-Net
- 1D-CNN
モデルの比較
モデルは、(1)正確に動作すること,(2)学習して効率的に推論すること,(3)最適化時間が短いこと(ハイパーパラメータのチューニングが速いこと)が求められます。
TabNet、DNF-Net、NODEの論文から9つのデータセットを使用し、各論文から3つのデータセットを使用します。さらに、これらの論文では使用されていない2つのKaggleデータセットを使用します。
深層学習モデルは他のデータセットにうまく一般化するか?
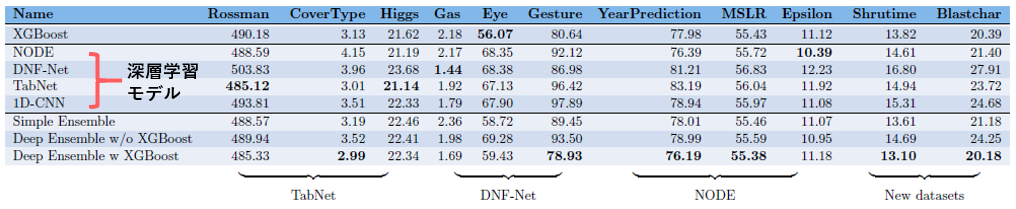
各データセットに対する各モデルの精度を示したものです(値が低いほど精度が高いことを示します)
・Simple Ensemble: XGBoost, SVM, Catboost
ほとんどの場合、データセットの元のモデルよりも、未知のデータセットでのモデルのパフォーマンスが悪くなっています。XGBoostモデルは、一般的に、深層モデルよりも性能が高かったです。また、深層学習モデルのアンサンブルとXGBoostは、ほとんどの場合、他のモデルを上回っています。
原著論文以外のデータセットで学習すると、深層学習モデルの性能はXGBoostよりも劣っています。
深層学習モデルのパフォーマンスが低下する理由
第一の可能性は選択バイアスです。各論文は、そのモデルが良く機能するデータセットで、そのモデルの性能を自然に示したのかもしれない。
二つ目の可能性は、ハイパーパラメータの最適化に違いがあることです。各論文は、その論文で紹介されているデータセットにおいて、より広範囲なハイパーパラメータの探索に基づいてモデルのハイパーパラメータを設定し、その結果、より良いパフォーマンスを得たのかもしれません。
ただ、各モデルのオリジナルのデータセットでの結果は、発表されたものと一致しました。
XGBoostとディープネットワークの両方が必要なのか?
ひとつの疑問は、XGBoostとディープモデルを組み合わせる必要があるのか、それとも非ディープモデルのシンプルなアンサンブルでも同じようなパフォーマンスが得られるのか、ということです。そこで、XGBoostとSVMとCatBoostのアンサンブルを学習しました。結果的に、古典モデルのアンサンブルは、ディープネットワークとXGBoostのアンサンブルよりもはるかに悪いパフォーマンスを示しています。
各モデルの未使用データセットにおける平均的な相対性能の低下
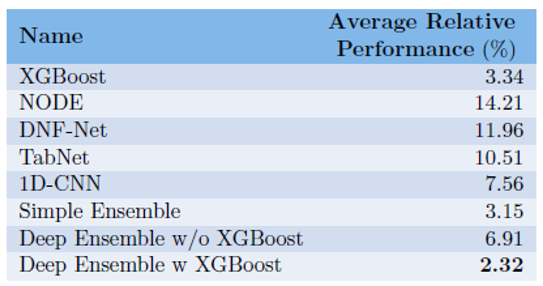
XGBoostは未知のデータセットに対しても性能の低下があまりないです。一方、深層モデルは未知のデータセットに対して、大きく精度が低下します。ただ、XGBoostと深層モデルのアンサンブルが一番性能の低下がないとうことがわかりました。
アンサンブル学習のためのモデル選択方法
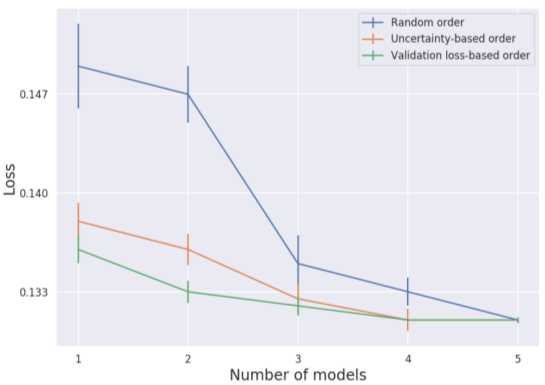
(1)検証損失に基づいて、検証損失の少ないモデルを最初に選択する方法
(2)各例のモデルの不確実性に基づいて、各例で(ある不確実性の尺度で)最も凝縮度の高いモデルを選択する方法
(3)ランダムな順序で選択する方法で
最も良い選択方法は、モデルの検証損失に基づいて予測値を平均化することでした。
最適化の難易度は?
現実では、新しいデータセットで使用するためにモデルを最適化する時間が限られていることがよくあります。これは、多くのデータセットで複数のモデルを実行するAutoMLシステムでは重要な考慮事項です。そこで、モデルの最適化にかかる反復回数の合計に注目しました。
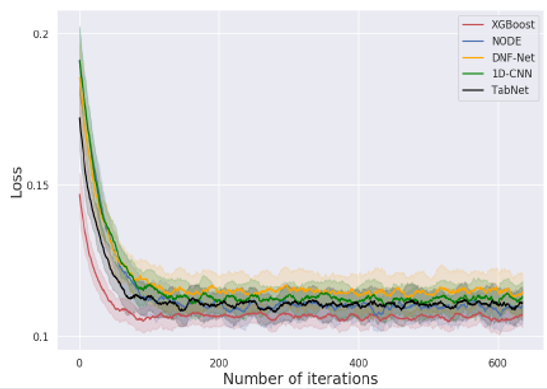
XGBoostはディープモデルよりも優れており、より早く(より少ない反復回数で,実行時間も短く)良好な性能に収束していることがわかります。
(1)ベイジアンのハイパーパラメータ最適化プロセスを使用したため、他の最適化プロセスでは結果が異なる可能性があります。
(2) XGBoost の初期ハイパーパラメータは,以前に多くのデータセットで最適化されているので、よりロバストである可能性があります。
(3) XGBoostモデルには、よりロバストで最適化しやすい固有の特性があるかもしれません。この挙動をさらに調査することは興味深いかもしれません。
まとめ
•深層モデルは,元の論文に登場していないデータセットでは弱く,ベースラインモデルであるXGBoostよりも弱いです。
•ただ、これらの深層モデルとXGBoostのアンサンブルはどのデータセットに対しても高い精度を出しました。
•このアンサンブルは,個々のモデルや「深層モデルではない」古典的なアンサンブルよりも,これらのデータセットで優れた性能を示しました。
•また、精度、推論の計算コスト、ハイパーパラメータの最適化時間の間のトレードオフの可能性について、いくつかの例を検討しました。
•結論として、表形式データに対する深層モデルの使用は大きな進歩を遂げていますが、XGBoostよりも優れているとは言えず、この分野ではさらなる研究が必要です。

