
NGBoost
公式ドキュメント
https://stanfordmlgroup.github.io/ngboost/intro.html
論文
https://arxiv.org/abs/1910.03225
分類
分類では、irisのデータセットを使っています。
fit関数にバリデーション用のデータを渡すことができます。
学習と予測
from ngboost import NGBClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from ngboost.distns import k_categorical
# データセットの呼び出し
load_data = load_iris()
X_train, X_val, y_train, y_val = train_test_split(load_data.data, load_data.target, test_size=0.2)
# 学習
ngb = NGBClassifier(
Dist=k_categorical(3),#分類のカテゴリ数
natural_gradient=True, # 自然勾配の使用の有無
n_estimators=100,
learning_rate=0.01,
).fit(X_train, y_train,X_val, y_val)
# ここではバリデーションデータとテストデータ同じものを使っています
X_test = X_val
y_test = y_val
# 予測
y_preds = ngb.predict(X_test)
y_dists = ngb.pred_dist(X_test)学習曲線の表示
import matplotlib.pyplot as plt
plt.figure(figsize = (10,8))
plt.plot(ngb.evals_result["train"]["LOGSCORE"], linewidth=3)
plt.plot(ngb.evals_result["val"]["LOGSCORE"], linewidth=3)
plt.title("iter vs loss")
plt.grid(True)
plt.xlabel("iter", fontsize=18)
plt.ylabel("loss", fontsize=18)
plt.tick_params(labelsize = 12)
plt.legend(("train", "val"), fontsize=18)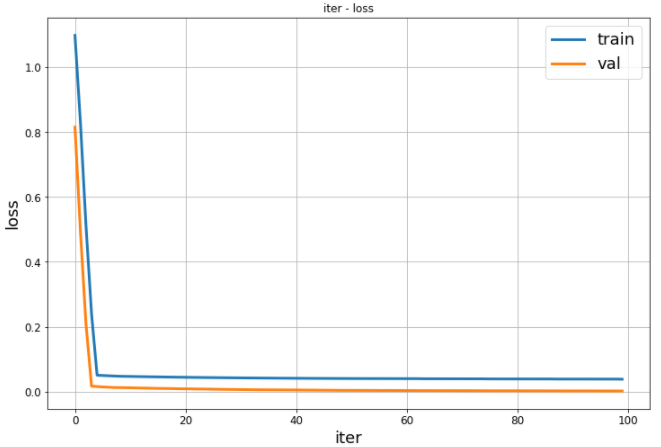
Feature Importance
import pandas as pd
import seaborn as sns
df_f = pd.DataFrame({
"columns" : load_data.feature_names,
"feature_importances_loc" : ngb.feature_importances_[0],
"feature_importances_std" : ngb.feature_importances_[1],})
# 平均に対するFeature Importance
df_loc = df_f.sort_values("feature_importances_loc", ascending=False)
plt.figure(figsize = (10,8))
plt.title('Feature importance(loc)')
sns.barplot(x = df_loc["feature_importances_loc"], y = df_loc["columns"])
plt.show()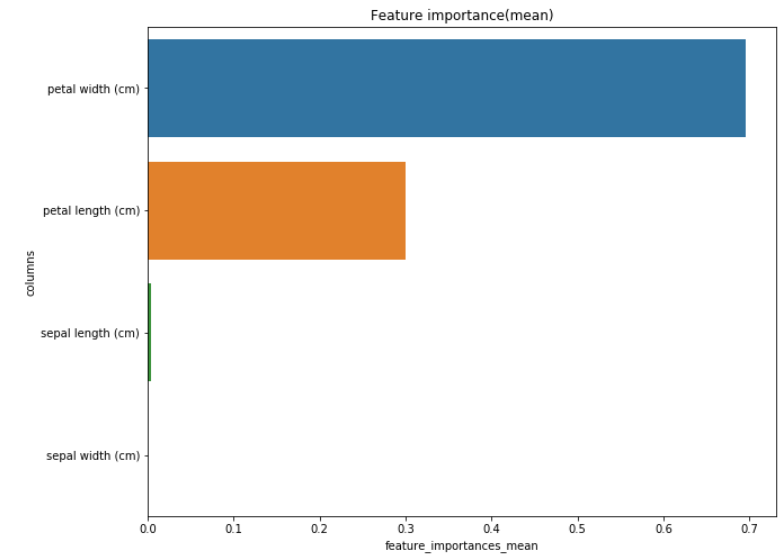
# 標準偏差に対するFeature Importance
df_std = df_f.sort_values("feature_importances_std", ascending=False)
plt.figure(figsize = (10,8))
plt.title('Feature importance(std)')
sns.barplot(x = df_std["feature_importances_std"], y = df_std["columns"])
plt.show()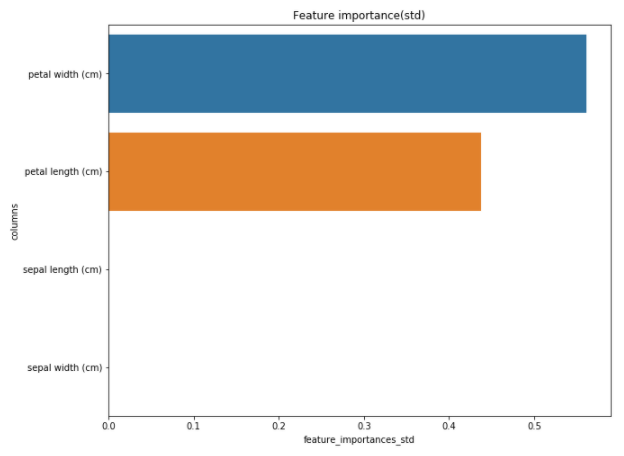
回帰
from ngboost import NGBRegressor
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# サンプルデータロード
load_data = load_boston()
X_train, X_val, y_train, y_val = train_test_split(load_data.data, load_data.target, test_size=0.2, random_state=42)
ngb = NGBRegressor(
n_estimators=100,
learning_rate=0.01,
).fit(X_train, y_train,X_val, y_val)
# ここではバリデーションデータとテストデータ同じものを使っています
X_test = X_val
y_test = y_val
# 予測
y_preds = ngb.predict(X_test)
y_dists = ngb.pred_dist(X_test)結果の表示
# test Mean Squared Error
test_MSE = mean_squared_error(y_preds, y_test)
print('Test MSE', test_MSE)学習曲線の表示
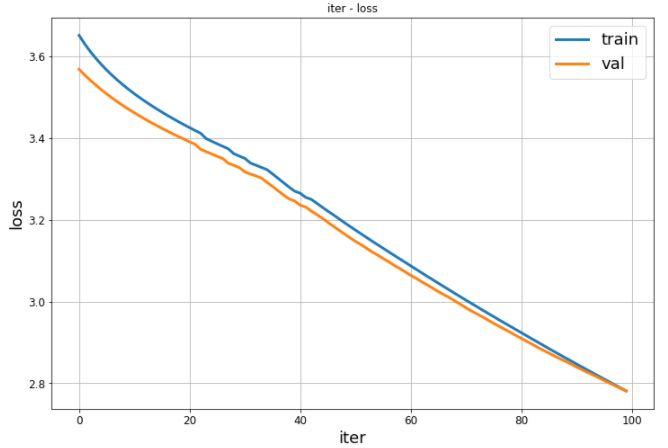
Feature Importance
import pandas as pd
import seaborn as sns
df_f = pd.DataFrame({
"columns" : load_data.feature_names,
"feature_importances_loc" : ngb.feature_importances_[0],
"feature_importances_std" : ngb.feature_importances_[1]})
# 平均に対するFeature Importance
df_loc = df_f.sort_values("feature_importances_loc", ascending=False)
plt.figure(figsize = (10,8))
plt.title('Feature importance(loc)')
sns.barplot(x = df_loc["feature_importances_loc"], y = df_loc["columns"])
plt.show()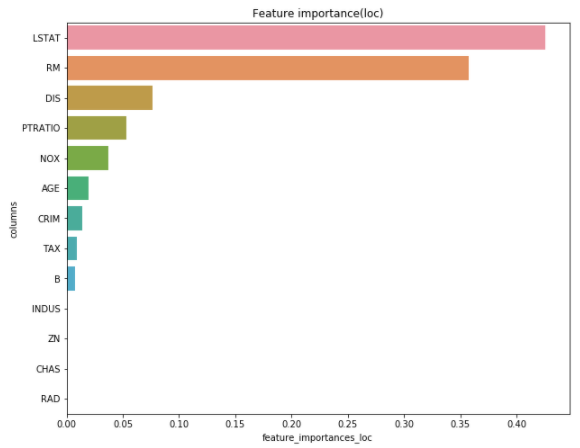
# 標準偏差に対するFeature Importance
df_std= df_f.sort_values("feature_importances_std", ascending=False)
plt.figure(figsize = (10,8))
plt.title('Feature importance(std)')
sns.barplot(x = df_std["feature_importances_std"], y = df_std["columns"])
plt.show()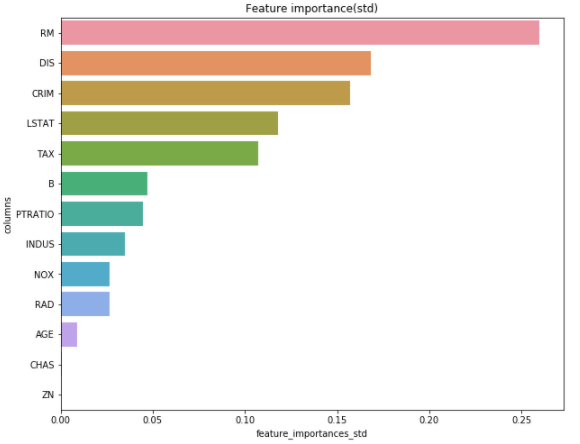
グラフの表示
import numpy as np
from tqdm import tqdm_notebook as tqdm
offset = np.ptp(y_preds)*0.1
y_range = np.linspace(min(y_val)-offset, max(y_val)+offset, 200).reshape((-1, 1))
dist_values = y_dists.pdf(y_range).transpose()
plt.figure(figsize=(25, 120))
for idx in tqdm(np.arange(X_val.shape[0])):
plt.subplot(35, 3, idx+1)
plt.plot(y_range, dist_values[idx])
plt.vlines(y_preds[idx], 0, max(dist_values[idx]), "r", label="ngb pred")
plt.vlines(y_val[idx], 0, max(dist_values[idx]), "pink", label="ground truth")
plt.legend(loc="best")
plt.title(f"idx: {idx}")
plt.xlim(y_range[0], y_range[-1])
plt.tight_layout()
plt.show()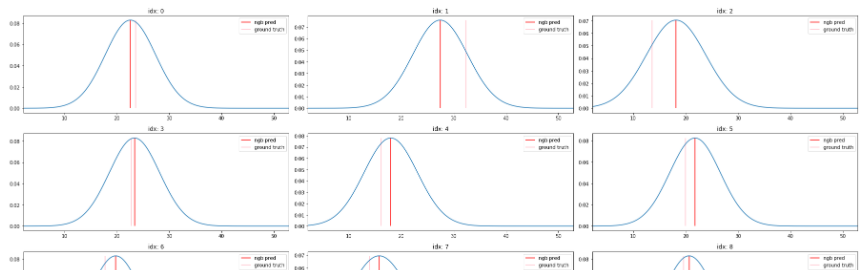
個数の指定
すべての予測に対して表示させると重くなる可能性があるので、最初から10個だけ表示させるようにしています。
import numpy as np
from tqdm import tqdm_notebook as tqdm
# 個数を指定
num = 10
offset = np.ptp(y_preds)*0.1
y_range = np.linspace(min(y_val)-offset, max(y_val)+offset, 200).reshape((-1, 1))
dist_values = y_dists.pdf(y_range).transpose()
plt.figure(figsize=(25, 120))
for idx in range(0,num):
plt.subplot(35, 3, idx+1)
plt.plot(y_range, dist_values[idx])
plt.vlines(y_preds[idx], 0, max(dist_values[idx]), "r", label="ngb pred")
plt.vlines(y_val[idx], 0, max(dist_values[idx]), "pink", label="ground truth")
plt.legend(loc="best")
plt.title(f"idx: {idx}")
plt.xlim(y_range[0], y_range[-1])
plt.tight_layout()
plt.show()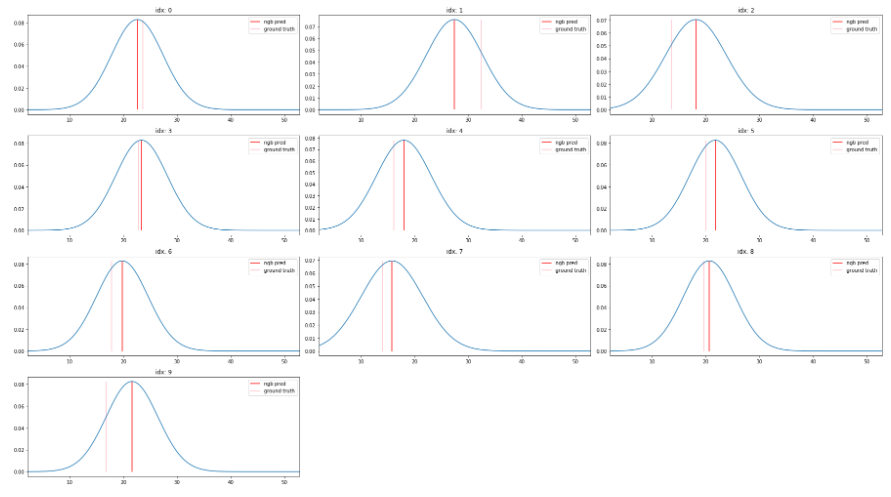
参考

NGBoost_regression_demo
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com

