
Kaggleのチュートリアル的なコンペ「Titanic: Machine Learning from Disaster」に挑戦してきました。Kaggleに参加するのは初めてなので、至らない所もあるかと思いますが、了承ください。一応スコアは0.79ぐらいは取れます。
0. コンペの概要
1912年に起きた、タイタニック号沈没事件を元にしたコンペになります。乗客の様々な情報から、生き残るか生き残れないかを予測します。
1. データの観察
1.1 ライブラリのインポートとデータの読み込み
まずは、必要なライブラリのインポートとトレーニングデータとテストデータを読み込みます。
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# データの読み込み
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")1.2データの概要確認
読み込んだら、全体の概要を把握しましょう。カラムの意味は以下の通りになります。
train.head(50)| カラム名 | 内容 | 詳細 |
| PassengerId | 乗客のID | |
| survived | 生存したかどうか | 1 = 生存、0 = 生存できなかった |
| Pclass | チケットのクラス | 1 = 1st、2 = 2nd、3 = 3rd |
| Name | 乗客の名前 | |
| Sex | 性別 | |
| Age | 年齢 | |
| Sibsp | 一緒に乗船した兄弟/配偶者の数 | |
| Parch | 一緒に乗船した親/子供の数 | |
| Ticket | チケット番号 | |
| Fare | 運賃 | |
| Cabin | キャビンの番号 | |
| Embarked | 乗船した港 | C = シェルブール、 Q = クイーンズタウン, S = サウサンプトン |
1.3 生存率
乗客の生存率がどれくらいあったのか円グラフにして見てみましょう。
plt.pie(train["Survived"].value_counts(), labels=["not Survived(0)", "Survived(1)"], startangle=90, counterclock=False, autopct='%1.1f%%',)全体の生存率は約38%であることが分かります。

1.4男女別の生存率
次は男女別の生存率を見て行きましょう。
sns.countplot('Sex' , hue = 'Survived', data = train)男性が高い確率でなくなっているのに対し、女性の生存率は高くなっていることがわかります。女性が優先的に救助されていることがわかります。

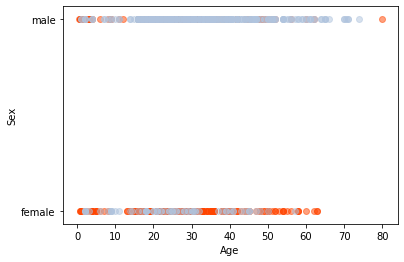
性別に加えて、年齢ごとの生存率を見たいので、横軸にAge、縦軸にSexをとって、Survivedによって色を分けてプロットします。
# 元データから、Survived、Sex、Ageだけ抜きとります。この際、欠損値のある行を削除しています。
df = train[["Survived", "Sex", "Age"]].dropna()
# Survided==1(生存者)のみ抽出
Survived = df.loc[df["Survived"] == 1]
Survived_age = Survived["Age"]
Survived_sex = Survived["Sex"]
# 横軸にAge、縦軸にSexをとって、散布図に赤でプロットします
plt.scatter(Survived_age, Survived_sex,color="#ff4500",alpha=0.5)
# 上と同じようにして、生き残れなかった人を青でプロットします。
df = train[["Survived", "Sex", "Age"]].dropna()
not_Survived = df.loc[df["Survived"] == 0]
not_Survived_age = not_Survived["Age"]
not_Survived_sex = not_Survived["Sex"]
plt.scatter(not_Survived_age, not_Survived_sex,color="#b0c4de",alpha=0.5)
plt.xlabel('Age')
plt.ylabel('Sex')赤いプロットが生存者で、青いプロットが生き残れなかった人です。こうしてみると、女性は全年齢に渡って、救助されていることがわかります。一方、男性の方は0~18歳の未成年に当たる範囲で、赤い点が確認できます。男性の中でも、年齢の低い人は救助される確率が高い事がわかります。
2. 欠損値の補完
2.1 欠損値の有無の確認
欠損値があると、モデルを構築する際にエラーになってしまうため、欠損値はないようにしておかなければなりません。まずは、欠損地の有無を確認しましょう。
train.isnull().sum()トレーニングデータの中にはAgeに177個、Embarkedに2個、Cabinに至っては687個とほとんど欠損している事がわかります。
欠損値の有無がわかったので、次からはこれらの欠損値を埋めて行きましょう。
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int642.2 Ageの欠損値の補完
最初はAgeの欠損値を補完していきます。まずは、欠損値が発生しているデータを確認します。
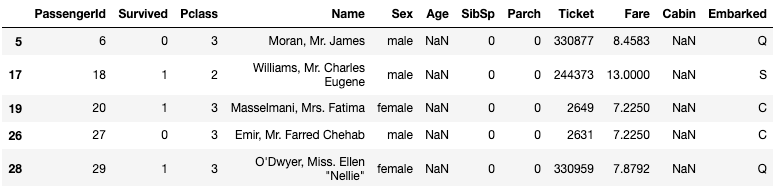
train[train["Age"].isnull()].head()ぱっと見る限り、生存したかどうかとは関係なさそうです。男女比もそんなに変わらなそうです。そもそも、名前までわかっていて、年齢だけわからないという状況がよくわかりません。 なので、これはコンペ側の人が課題として、わざと欠損値をつくっているのかもしれません。
欠損値を何で埋めるかですが、中央値を使う事が多いです。 全体の年齢の中央値を欠損値に代入してもいいですが、ここは少し工夫してPclassに注目してみます。
Pclassはチケットのクラスを示していて、1が一番高いクラスです。おそらく、Pclassが高いとチケットの値段も高くなるため、それを購入した年齢層も高くなるのではないかと、予測します。
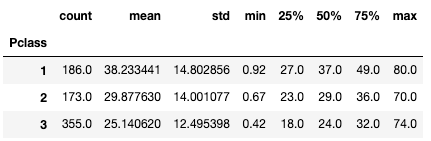
そこで、PclassごとのAgeの中央値などを見てみます。
train.groupby("Pclass").describe()["Age"]すると、やはりPclassのランクが高くなるにつれて、年齢の中央値も大きくなっています。全体の年齢の中央値は28歳なので、そのまますべてに入れていたら、かなり大きな違いになったかもしれません。
この結果より、Pclassごとに年齢の中央値を補完していきましょう。
トレーニングデータのNaNとなっているAgeだけに、Pclassごとの中央値を代入していきます。
# Ageの欠損値へPclassごとのAgeの中央値を代入
train.loc[train["Age"].isnull(), 'Age'] = train.groupby("Pclass")["Age"].transform('median')Ageの欠損値を確認してみると、なくなっているのがわかります。
train.isnull().sum()PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int642.3 Cabinの欠損値の補完
次はCabinの欠損値を埋めていこうと思います。 まず、生存状況とCabinに関係性があるのか調べていきます。ただ、Cabinの種類は多いので、簡単にするために頭文字のアルファベットのみを抽出して、アルファベットごとにグループを作るようにします。
# トレインデータからCabinとSurvivedだけ切り取ります
cabin = train[["Cabin", "Survived"]]
# Cabinの頭文字(str(x)[0])を抽出し、Cabin_initというカラムを作成します。
cabin["Cabin_init"] = cabin["Cabin"].map(lambda x:str(x)[0])それでは、Cabinの頭文字ごとの生存率を見てみます。
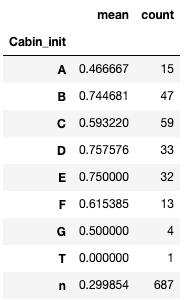
# Cabin_initごとのSurvivedを確認します。
cabin["Survived"].groupby(cabin["Cabin_init"]).agg(["mean", "count"])全体の生存率が38%にくらべて、B、D、Eは生存率がかなり高い気がしますね。また、nはデータがない(NaN)を意味しているので、Cabinが欠損している人達の生存率になります。すると、nの生存率は29%と他のに比べても、全体と比べても低い生存率であることがわかります。
今回はCabinのデータがある人を1とし、ない人を0として、二種類に分けることにします。
lambdaの中が少しわかりづらいので、lambdaの中を説明したいと思います。
lambdaの中の条件式は、もしx == xだったら、1を返し、そうでなかったら0を返します。もし、キャビンに値が何かしら入っていれば、x==xがなりたつので、1になります。しかし、キャビンの値が欠損していた場合、NaNが入っています。NaN==NaNは実はFalseなので、0が代入されます。
これらより、欠損しているところには0が入り、何かしらの値が入っていたところには1が入ります。
これで、Cabinの欠損値がなくなりました。
train["Cabin"] = train["Cabin"].map(lambda x: 1 if x == x else 0)2.4 Embarkedの欠損値の補完
次に、Embarkedの欠損値を見ていきます。先ほどと同じようにEmbarkedごとの生存率を見ていきましょう。
train["Survived"].groupby(train["Embarked"]).agg(["mean", "count"])すると、”C”の生存率だけが高く、偏っているように見えます。しかし、”S”の値の数が644個と圧倒的に多いので、欠損値は”S”で埋めることにします。
train["Embarked"] = train["Embarked"].fillna("S")最後に欠損値がなくなったか確かめてみましょう。
train.isnull().sum()これで、トレインデータから全ての欠損値がなくなりました。
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int643. データの整理
3.1 SexとEmbarkedのグルーピング
カテゴリ変数とはグループやカテゴリを表す変数のことです。
SexやNameはカテゴリ変数なので、このままではモデルの構築には使えません。なので、これらを数値化し、グルーピングしていかなければなりません。
まずは、簡単なSexとEmbarkedを数値化していきます。
Sexはmaleは1に、femaleは0に変換します。Embarkedは”S”を0、2C”を1、”Q”を2に変換します。
train['Sex'] = train['Sex'].apply(lambda x: 1 if x == 'male' else 0)
train['Embarked'] = train['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int)
train.head()3.2 Nameのグルーピング
続いて、Nameに関してです。これは処理に悩みます。列ごと削除してモデル構築に使わないという手もあります。しかし、最初のほうで分析した通り、性別によって、生存率は大きく変わってきます。女性のほうが生存率が高く、男性の生存率は低いのでした。また、年齢も生存するかどうかにかかわってきます。なので、ここも何とかしたいところです。ここで、Nameをみてみると、先頭から二番目にMrやMrsなどの敬称があることがわかります。まずはこの部分を切り取ってみましょう。
#敬称(Title)の抽出
Title = train[["Survived", "Name"]]
Title["Name"] = train["Name"].map(lambda x: x.split(', ')[1].split('. ')[0])次にどんな敬称があるのか見ていきましょう。
敬称中で、一般的なものはMr,Miss,Mrs,Masterの4つでしょうか。それ以外の敬称は数も少ないので、Otherにまとめてしまおうと思います。
Title["Name"].value_counts()
Mr 517
Miss 182
Mrs 125
Master 40
Dr 7
Rev 6
Major 2
Col 2
Mlle 2
Sir 1
Don 1
Mme 1
Ms 1
Lady 1
Jonkheer 1
Capt 1
the Countess 1
Name: Name, dtype: int64replace関数を使って、数の少ない敬称を”Others”に変換しています。
Title["Name"] = Title["Name"].replace(["Dr", "Rev", "Major", "Col", "Mlle", "Jonkheer", "Ms", "Capt", "Mme", "Sir", "Don", "Lady", "the Countess"], "Others")
Title["Name"].value_counts()Mr 517
Miss 182
Mrs 125
Master 40
Others 27
Name: Name, dtype: int64これで、敬称の整理が終わりました。なので、ここで敬称別の生存率を見てみましょう。女性の敬称であるMissやMrsは高い傾向にあります。特に既婚女性を差すMrsの生存率が高いですね。これは、年齢層が高いからだと思います。また、男性でも年配に使われるMasterの人の生存率は高いですが、Mrはとても低くなっていますね。
Title["Survived"].groupby(Title["Name"]).agg(["mean", "count"])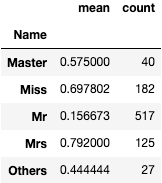
Embarkedと同じように、敬称ごとに数値を割り当てていきましょう。
Title['Name'] = Title['Name'].map( {"Master": 0 , "Miss":1 , "Mr":2, "Mrs":3, "Others":4})
Title.head()最後に、Titleを元のトレーニングデータに戻します。
トレーニングデータを見てみると、Nameが数値化しているのが確認できます。
train["Name"] = Title["Name"]
train.head()
3.3 Ticketの削除
最後にTicketが残っていますが、いまひとつ規則性などがわからないので、今回は除外してしまいましょう。
train = train.drop(["Ticket"], axis = 1)3.4 モデル構築のためのデータの分離
ここまでトレーニングデータのすべてを数値化できました。最後にモデル構築のためにすこしだけデータを整理していきましょう。
まず、説明変数となるものをtrain_xに、目的変数にtrain_yを入れましょう。Survivedが目的変数にあたります。説明変数はSurvivedとPassengerIdを削除したものになります。PassengerIdは使わないので、消してしまいましょう。
# PssengeIdを削除します
train = train.drop([ "PassengerId"] , axis = 1)
# 目的変数であるSurvivedをtrain_yに代入します。
train_y = train["Survived"]
# Survivedを削除して残ったものが説明変数となります。
train_x = train.drop([ "Survived"] , axis = 1)
train_x.head()4. テストデータの前処理
4.1 テストデータへの前処理の適用
ここまでのことをテストデータにも同じように適用させます。トレーニングデータと違うところは、”Survived”のカラムがないことですね。 まずは欠損値がないか確かめてみましょう。
すると、Age、Cabin、 Fareに欠損値があることがわかります。AgeとCabinはトレーニングデータとおなじようにして、欠損値を埋めていきましょう。Fareについては、欠損値は一つだけなので、中央値で埋めてしまいましょう。
test.isnull().sum()PassengerId 0
Pclass 0
Name 0
Sex 0
Age 86
SibSp 0
Parch 0
Ticket 0
Fare 1
Cabin 327
Embarked 0
dtype: int64Nameの欠損値を埋めるための前準備として、敬称を抜き取り、何の敬称があるか確認します。
test["Name"] = test["Name"].map(lambda x: x.split(', ')[1].split('. ')[0])
test["Name"].value_counts()Mr 240
Miss 78
Mrs 72
Master 21
Rev 2
Col 2
Dona 1
Ms 1
Dr 1
Name: Name, dtype: int64テストデータの処理は、一気に今までしてきた処理を行ってしまいます。
#Cabinの欠損値の補完
test["Cabin"] = test["Cabin"].map(lambda x: 1 if x == x else 0)
#Ageの欠損値の補完
test.loc[test["Age"].isnull(), 'Age'] = train.groupby("Pclass")["Age"].transform('median')
#Fareの欠損値の補完
test["Fare"] = test["Fare"].fillna(test["Fare"].median())
#カテゴリ変数SexとEmbarkedの変換
test['Sex'] = test['Sex'].apply(lambda x: 1 if x == 'male' else 0)
test['Embarked'] = test['Embarked'].map( {'S': 0 , 'C':1 , 'Q':2}).astype(int)
#Nameの変換
test["Name"] = test["Name"].replace(["Rev", "Col", "Dr", "Dona", "Ms"], "Others")
test["Name"] = test["Name"].map( {"Master": 0 , "Miss":1 , "Mr":2, "Mrs":3, "Others":4})
#TicketとPassengerIdの削除
test = test.drop(["Ticket", "PassengerId", "Name"] , axis = 1)
test.isnull().sum()Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Cabin 0
Embarked 0
dtype: int64これで、欠損値を埋め、カテゴリ変数を数値化しました。長々と説明してきましたが、まとめて書くと、コードの量はこの程度になります。
最後にモデルの構築と予測をして終わりにしましょう。
5. 分析モデルの構築と予測
5.1 分析モデルの構築と予測
ようやく分析を行います。今回はランダムフォレストを使います。パラメータの細かい調整などは行わないで、サクッとおわらすことにします。
from sklearn.ensemble import RandomForestClassifier
# モデルの構築
model1 = RandomForestClassifier(n_estimators = 10,max_depth=5,random_state = 0)
# モデルの学習
model1.fit(train_x, train_y)
# 予測
predictions = model1.predict(test)5.2 提出用データの作成
最後に提出用のデータを作成して終了です。提出データには、テストデータのPassengerIdと先ほど予測したSurvivedの結果が必要です。
sub = pd.read_csv("test.csv")
submission = pd.DataFrame({"PassengerId": sub["PassengerId"], "Survived": predictions})
submission.to_csv("submission_part1.csv", index = False)5.3 結果
You advanced 10,157 places on the leaderboard!
Your submission scored 0.78947, which is an improvement of your previous score of 0.76555. Great job!
スコアは0.78947とサンプルを提出したときの0.76555より伸ばすことができました!上位22%の成績みたいです。もっと上のスコアを目指すために、さらに分析を進めていきたいと思います。
6. もっとよくする
6. 1 ランダムフォレストのパラメータ調整(n_estimators)
試しに、ランダムフォレストのパラメータであるn_estimatorsを100にしてみましょう。
from sklearn.ensemble import RandomForestClassifier
# モデルの構築(n_estimatorsを100にしました)
model1 = RandomForestClassifier(n_estimators = 10,max_depth=5,random_state = 0)
# モデルの学習
model2.fit(train_x, train_y)
# 予測
predictions = model2.predict(test)
predictions
sub = pd.read_csv("test.csv")
submission = pd.DataFrame({"PassengerId": sub["PassengerId"], "Survived": predictions})
submission.to_csv("submission_part2.csv", index = False)すると、それだけでスコアが0.79425まであがり、0.8手前まできました。上位15%の成績です。
ランダムフォレストの場合、基本的にはn_estimatorsは大きければ大きいほうが良いです。より多くの決定木の平均をとることで、過剰適合が軽減されていくからです。しかし、増やすことによる利益は徐々に減っていきますし、訓練にかかる時間も増大します。なので、時間とメモリと相談して値を決めましょう。
また、下記のようにすれば、モデルのスコアも出力できます。Kaggleでは一日に提出できる回数は制限があるので、自分でスコアを確認してから、提出するようにすれば、提出する回数を減らすことができます。ただし、このスコアが上がったからと言って、Kaggleのほうのスコアも上がるとは限りません。
model2.score(train_x, train_y)
acc_random_forest = round(model2.score(train_x, train_y) * 100, 2)
acc_random_forest85.977. 参考
Kaggleでは公開されている他の人のnoteやコードをみる事ができます。英語ですが、Google翻訳を駆使すれば、理解できると思います。今回は、以下の人のノートを参考にしました。

